Anomaly detection is a technique used in data analysis to identify patterns or data points that deviate significantly from what is expected or considered normal within a dataset. By monitoring these deviations, anomaly detection helps to spot irregularities, such as fraud, system failures, or unexpected behavior, that may indicate underlying problems or opportunities. This method is widely applied in various fields, including cybersecurity, finance, healthcare, and industrial monitoring. It can be used to detect issues in real-time, providing early warnings for proactive measures, thus improving decision-making and enhancing system reliability.
Anomaly detection leverages artificial intelligence to identify deviations from established behavioral patterns, classifying them as anomalies. Dynatrace’s AI-driven approach not only detects these anomalies but also autonomously establishes baselines, determines root causes, and triggers alerts for swift remediation.
Traditional, reactive methods that rely on static thresholds fail in today’s dynamic, multicloud ecosystems, where containerized applications and microservices continuously evolve. Defining “normal” behavior in such environments is a moving target, making conventional alert systems prone to false positives and inefficiencies.
Dynatrace overcomes these challenges with AI-driven monitoring that dynamically adapts to real-time changes in system topology. Through multidimensional baselining, dynamic dependency detection, and predictive analytics, it continuously learns system behaviors, identifying anomalies based on meaningful metrics.
This advanced approach eliminates noise from static threshold alerts, reducing false positives while detecting even the most elusive anomalies. With end-to-end monitoring and automated intelligence, Dynatrace ensures proactive issue resolution, enhancing system reliability and operational efficiency.
Types of Anomalies in Time Series
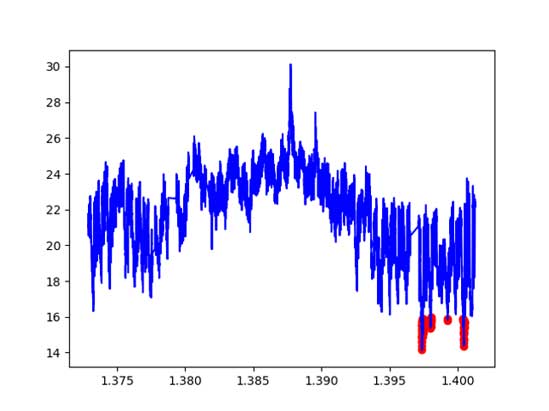
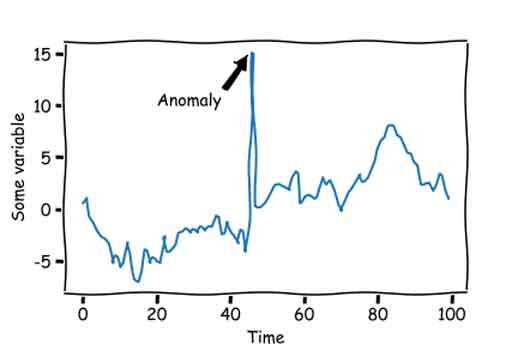
Point Anomalies: Data points that significantly differ from the rest, such as a sudden spike in banking transactions, which may indicate fraud.
Contextual Anomalies: Data points that are unusual in a specific context but normal in others, such as a sharp temperature drop being considered an anomaly in summer but not in winter.
Collective Anomalies: A group of related data points that, when considered together, appear anomalous, such as an unusually high number of transactions within a short period, which could suggest fraudulent activity.
Understanding these types is essential for selecting the appropriate anomaly detection method. Statistical models are more suitable for detecting point anomalies, while machine learning algorithms are better suited for contextual and collective anomalies.
Categories of Anomaly Detection
Supervised Anomaly Detection: The model is trained on labeled data (normal and anomalous instances), but due to the rarity of anomalous data, this approach is less common.
Semi-Supervised Anomaly Detection: The model is trained only on normal data and identifies deviations as anomalies. This approach is more practical than supervised methods.
Unsupervised Anomaly Detection: It does not require labeled data and identifies anomalies based on deviations from established data patterns. Techniques such as clustering, Isolation Forest, and Local Outlier Factor (LOF) fall under this category.
Key Anomaly Detection Methods
Statistical Methods: Techniques like Z-Score are used to detect outliers in datasets with a Gaussian distribution.
Density-Based Methods: Includes Local Outlier Factor (LOF), which compares data point densities to identify anomalies.
Isolation Forests: Randomly isolates data points to distinguish anomalies from normal data, making it efficient for large datasets.
One-Class Support Vector Machine (OCSVM): Effective for anomaly detection in high-dimensional data when anomalies are rare.
Neural Networks: Includes Autoencoders for data compression and reconstruction, and LSTMs for detecting anomalies in time-series data.
Bayesian Networks: Models probabilistic relationships between features to detect unexpected deviations.
Hidden Markov Models (HMMs): Used for anomaly detection in sequential data, such as speech analysis and temporal behavior modeling.
Anomaly detection presents multiple challenges, making it a complex problem. While the primary goal is to define normal behavior and identify deviations, several factors complicate this process. Some of the major challenges include:
Defining the Normal Region: Precisely determining the boundary between normal and anomalous behavior is difficult, especially with gradual behavioral changes.
Anomaly Camouflage: In some cases, anomalies are intentional (e.g., malicious activities) and are designed to appear normal.
Variability in Normal Behavior: Normal behavior evolves over time, making pre-trained models obsolete after a period.
Lack of Labeled Data: Insufficient labeled data for training and evaluating anomaly detection models is a major limitation.
Noise in Data: Distinguishing anomalies from noisy data is challenging, as noise can resemble real anomalies.
Data Imbalance: Anomalous data is significantly less frequent than normal data, leading to issues such as the Accuracy Paradox.
Defining and Labeling Anomalies: In unsupervised learning, precisely defining anomalies and labeling data is particularly challenging.
Dynamic Data and Concept Drift: Changes in data distribution over time reduce the accuracy of anomaly detection models.
Cost-Sensitive Evaluation: In some applications, false positive and false negative errors have different costs, necessitating evaluation metrics that account for these discrepancies.